Agent Ai全栈开发记录


持续更新 star感谢!
关于该Agent系统的想法
该系统灵感由大创项目而来 具体目标是 RAG + MCP 的合同校审Agent
我将该项目扩大为公司内部合同校审的SaaS平台
写完这一版后把后端平台重构为Java来承接 并尝试使用RPC进行调用
这样我的RPC也有了真实的使用场景
模型(现在先调api 以后美美白嫖老师的服务器用ollama):
Qwen-max Qwen-text-embedding-v4 Qwen-rerank-v3
关于基础
看了一点hello agent 也多了解了一下概念之类的东西 觉得亲手做更好更沉浸理解本质 所以开始做
我认为这种就是一个对话agent主要流程的链路
包括多轮对话 记忆 通过input调用工具 generate之后append进对话历史 再来下一轮
while true:
user_input = get_user_input()
history.append({"role": "user", "content": user_input})
update_memory(user_input)
action = planner(user_input, history, memory)
if action == "tool":
tool_result = call_tool(user_input)
else:
tool_result = None
reply = llm_generate(history, memory, tool_result)
history.append({"role": "assistant", "content": reply})
print(reply)
agent链路伪代码
关于前端
0经验前端 这个我真得好好开一个讲讲为什么codex是区了
不是哥们 谁懂codex的前端登录直接post明文密码 谁懂
关于流程
员工登录校验 -> 提交合同 -> 首先会去自动审查一遍 -> 可以进行进一步对话 agent编排下一步行动 -> 循环以上校审流程完善合同 -> 交给管理员/审核员 -> 借助刚刚的agent功能 + 人为最终审核 -> 审核流程结束
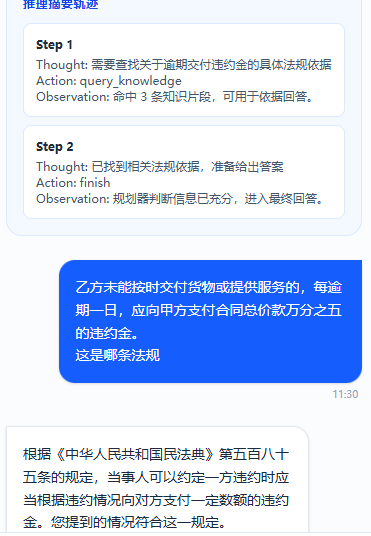
一开始就是简单的ReAct流程 Thought - Action - Observation
关于RAG
切割思路:
Format: 章 / 大标题 / 小标题 / 某条法案
Overlap: 未考虑
因为感觉这种format不会切碎,对“按法条切”的法律库,通常提升有限。因为 chunk 边界天然是法条边界,不是随机切碎文本。overlap 更适合“固定长度窗口切块”场景(防止语义被截断)。而且我觉得我的format对于条和条之间的关系做的也相对来说比较好。
现在第一版只是用qwen-embedding-v4跑了一遍向量进了milvus 没有使用BM25和rerank
- 检索方式:向量检索(dense retrieval)
- 通过 ContractKnowledgeRetriever.retrieve_documents -> vector_store.similarity_search
- 向量后端支持 Milvus / FAISS,默认是 Milvus(VECTOR_BACKEND 默认 milvus)
- 嵌入模型是 text-embedding-v4(Qwen 兼容接口)
- Top-k:
- 线上 ReviewService / ChatService 默认都是 k=3
然后我们要检测一下我们的召回率 让我们的回答更有迹可循有知识库支撑
写了50条召回测试用例 gpt生成的
我目测了一下gold对应的怎么样 然后补了一些对应gold
主要是gpt在租赁条款那边有点没偏重租赁部分的法规 反而全集中最基础的合同部分
(后改 在人事条款页也很没偏重人事部分 我没看到!)
更改测试用例之后 我第一版直接dense召回开搜结果大概是下面这样
- Recall@1: 0.44
- Recall@3: 0.70
- Recall@5: 0.80
- 命中数:hits@1=22, hits@3=35, hits@5=40
- 采购合同:R@5=0.70
- 服务合同:R@5=0.70
- 保密协议:R@5=0.60
- 租赁合同:R@5=1.00
- 劳务合同:R@5=1.00
这个top5出现概率还可以 但是top1很差 证明主要的条款已经在前面出现 但是dense出来的结果不靠前 考虑了rerank 上了一下 qwen-rerank-v3
第二版dense出来rerank结果是这样
- order_changed_count = 50/50
- success_count = 50
总体对比(with_rerank_v3 vs vector_only)
- Recall@1: 0.44 -> 0.66(+0.22)
- Recall@3: 0.70 -> 0.78(+0.08)
- Recall@5: 0.80 -> 0.84(+0.04)
- MRR: 0.578333 -> 0.731667(+0.153334)
- NDCG@3: 0.526008 -> 0.676126(+0.150118)
- NDCG@5: 0.561250 -> 0.697473(+0.136223)
- avg_first_hit_rank: 1.825 -> 1.380952
耗时
- 18.66s -> 42.05s(增加约 +23.39s)
不过我认为这种场景下准确性更重要 用户体验耗时后续看怎么压
MRR NDCG都在提 first hit rank也被提了很多 证明召回rerank被证明为有效
我第一感觉把dense池子从12开的更高会让调用变慢成本变高
所以为了精选这12条我应该上hybrid 而不是选择扩池
上了BM25 K1 = 1.5 b = 0.75
由于是法条类chunk 所以b的影响应该相对更明显
- Recall@1: 0.66 vs 0.66(+0.00)
- Recall@3: 0.78 vs 0.78(+0.00)
- Recall@5: 0.88 vs 0.84(+0.04,44 vs 42,多命中2条)
- NDCG@3: 0.679758 vs 0.676126(+0.003632)
- NDCG@5: 0.72395 vs 0.697473(+0.026477)
- MRR: 0.744 vs 0.731667(+0.012333)
- 耗时:34.00s
简单调了一下算法参数我看这个recall5死活上不去 就看了被drop的misscall
然后一看好像找的比我gold还准... 快速改了一下又看了一眼最终结果大概是这样
- Recall@1 = 0.70(35/50)
- Recall@3 = 0.90(45/50)
- Recall@5 = 0.98(49/50)
- NDCG@3 = 0.746908
- NDCG@5 = 0.790776
- MRR = 0.816667
然后我要压时间 这时候我们应该思考时间在哪部分花费的比较严重 我选择rerank调用阶段 喂给rerank的条数应该尽可能少,并且尽可能让需要被rerank的query去re
所以我简单判断了 如果bm25和dense出来的top1相同 直接skip的做法
- short_circuit_dense_bm25_top1_agree 触发:14/50(28%)
- 实际发生 rerank:36/50
- 在这 36 条里,rerank_request_seconds 平均 0.380487s(p95 0.42659s,max 0.620984s)(几乎全是网络+服务端)
不知道再skip狠一点有没有用 感觉接口延迟还是有点高
关于数据库选型
Milvus 的主要优势
- 面向向量检索的专用库,目标就是高性能和大规模(官方定位到 very large scale)。
- 多向量/混合检索能力成熟(Milvus 2.4+ 支持多向量 hybrid_search + RRF/Weighted 重排)。
- 支持标量过滤(布尔表达式)和向量检索结合,适合合同场景里的 合同类型/条款字段/状态 过滤。
- 索引策略选择多(HNSW、IVF_PQ、HNSW_PQ 等),能按“速度/召回/内存”调参。
- 开源可自托管,数据可控,适合有合规要求的企业场景。
编写过程中的思考
1.第一个问题 —— 我们agent做任务的终止态如何界定? 通过第一版自我迭代扔进去的循环结果来看 这个终止态界定的并不算好 我觉得需要人来干预一个line让他停下来 像我们这种问答 / RAG agent来说 终止依据应该如下:
- 已经能回答问题
- 有足够证据支撑
- 新检索不再增加有效信息
- 达到检索轮数上限
作为这个reAct范式的agent 我设定是有对应的action让他报备自己在做什么动作 有一个action 而我们可用的tools会封装为统一的格式 那我引入了MCP
然后我们的最大轮数默认为3 如果llm发送终止态即可停下 或者我们可以让它判断完已有应需要的东西也可以提前停下 目前没做这个

